CONTENTS
备注:
本读书笔记基于侯捷先生的《STL源码剖析》,截图和注释版权均属于原作者所有。
本读书笔记中的源码部分直接拷贝自SGI-STL,部分代码删除了头部的版权注释,但代码版权属于原作者。
小弟初看stl,很多代码都不是太懂,注释可能有很多错误,还请路过的各位大牛多多给予指导。
为了降低学习难度,作者这里换到了SGI-STL-2.91.57的源码来学习,代码下载地址为【 http://jjhou.boolan.com/jjwbooks-tass.htm 】
SGI-STL中的hashtable使用的是开链法应对hash冲突,如下图,这里简单的笔记下代码。
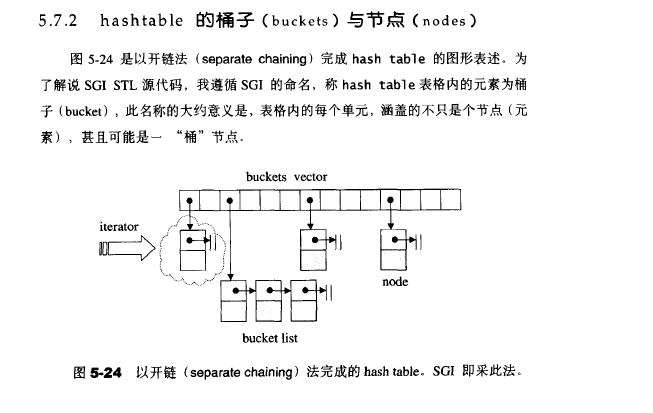
stl_hashtable.h:
//hashtable中储存值的节点类。
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;//开链法存储,指向链表中的下一个节点。
Value val;
};
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc = alloc>
class hashtable;
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator;
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_const_iterator;
//hashtable的iterator类
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>
hashtable;
typedef __hashtable_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
iterator;
typedef __hashtable_const_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
const_iterator;
typedef __hashtable_node<Value> node;//注意这里的node的定义,其实就是__hashtable_node
typedef forward_iterator_tag iterator_category;
typedef Value value_type;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef Value& reference;
typedef Value* pointer;
node* cur;//iterator指向的节点
hashtable* ht;//iterator所属的hashtable
__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}
__hashtable_iterator() {}
reference operator*() const { return cur->val; }//对iterator解引用,返回的是指向节点的实际存储值。
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }
};
//hashtable的iterator类 const类型的
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_const_iterator {
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>
hashtable;
typedef __hashtable_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
iterator;
typedef __hashtable_const_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
const_iterator;
typedef __hashtable_node<Value> node;//注意这里的node的定义,其实就是__hashtable_node
typedef forward_iterator_tag iterator_category;
typedef Value value_type;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef const Value& reference;
typedef const Value* pointer;
const node* cur;
const hashtable* ht;
__hashtable_const_iterator(const node* n, const hashtable* tab)
: cur(n), ht(tab) {}
__hashtable_const_iterator() {}
__hashtable_const_iterator(const iterator& it) : cur(it.cur), ht(it.ht) {}
reference operator*() const { return cur->val; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
const_iterator& operator++();
const_iterator operator++(int);
bool operator==(const const_iterator& it) const { return cur == it.cur; }
bool operator!=(const const_iterator& it) const { return cur != it.cur; }
};
//hash链表的数目,即数据hash之后的可能最大值。这里一共有28个。
//如果当前的链表数目下碰撞太多,就把链表数目扩充到下一个值上。
// Note: assumes long is at least 32 bits.
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473ul, 4294967291ul
};
//取n的下一个可取的链表数目值。
inline unsigned long __stl_next_prime(unsigned long n)
{
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
//hashtable类
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc>
class hashtable {
public:
typedef Key key_type;
typedef Value value_type;
typedef HashFcn hasher;
typedef EqualKey key_equal;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type& reference;
typedef const value_type& const_reference;
hasher hash_funct() const { return hash; }
key_equal key_eq() const { return equals; }
private:
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
typedef simple_alloc<node, Alloc> node_allocator;
vector<node*,Alloc> buckets;//buckets表示的是hashtable的节点链表的vector,它的每个元素都是一个node*,代表一个链表,即是开链法实现中的链表。
size_type num_elements;//hashtable中的节点的数量
public:
typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey,
Alloc>
iterator;
typedef __hashtable_const_iterator<Value, Key, HashFcn, ExtractKey, EqualKey,
Alloc>
const_iterator;
friend struct
__hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>;
friend struct
__hashtable_const_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>;
public:
//构造函数
hashtable(size_type n,
const HashFcn& hf,
const EqualKey& eql,
const ExtractKey& ext)
: hash(hf), equals(eql), get_key(ext), num_elements(0)
{
initialize_buckets(n);
}
hashtable(size_type n,
const HashFcn& hf,
const EqualKey& eql)
: hash(hf), equals(eql), get_key(ExtractKey()), num_elements(0)
{
initialize_buckets(n);
}
//拷贝构造函数
hashtable(const hashtable& ht)
: hash(ht.hash), equals(ht.equals), get_key(ht.get_key), num_elements(0)
{
copy_from(ht);
}
//赋值构造函数
hashtable& operator= (const hashtable& ht)
{
if (&ht != this) {
clear();
hash = ht.hash;
equals = ht.equals;
get_key = ht.get_key;
copy_from(ht);
}
return *this;
}
//析构函数,清除hashtable中的所有数据
~hashtable() { clear(); }
//返回hashtable的节点的数量
size_type size() const { return num_elements; }
//hashtable的最多的节点数目,由于节点是动态申请的,因此最大的节点的数量和内存有关。
size_type max_size() const { return size_type(-1); }
//hashtable是否为空
bool empty() const { return size() == 0; }
void swap(hashtable& ht)
{
__STD::swap(hash, ht.hash);
__STD::swap(equals, ht.equals);
__STD::swap(get_key, ht.get_key);
buckets.swap(ht.buckets);
__STD::swap(num_elements, ht.num_elements);
}
//返回hashtable的起始iterator。
iterator begin()
{ //循环查找vector中的第一个有值的链表(开链法)。
for (size_type n = 0; n < buckets.size(); ++n)
if (buckets[n])
return iterator(buckets[n], this);//将该链表的第一个元素构成iterator,返回。
return end();//如果vector中一个链表都没有,就返回end()
}
//返回hashtable的终止iterator。
iterator end() { return iterator(0, this); }
//返回hashtable的起始iterator。
const_iterator begin() const
{
for (size_type n = 0; n < buckets.size(); ++n)
if (buckets[n])
return const_iterator(buckets[n], this);
return end();
}
const_iterator end() const { return const_iterator(0, this); }
friend bool
operator== __STL_NULL_TMPL_ARGS (const hashtable&, const hashtable&);
public:
//返回hashtable的链表的数目。
size_type bucket_count() const { return buckets.size(); }
//返回hashtable的最大的链表的数目。
size_type max_bucket_count() const
{ return __stl_prime_list[__stl_num_primes - 1]; }
//返回特定连表上的节点的数目。
size_type elems_in_bucket(size_type bucket) const
{
size_type result = 0;
for (node* cur = buckets[bucket]; cur; cur = cur->next)
result += 1;
return result;
}
//插入一个元素,有相同的元素则返回。
pair<iterator, bool> insert_unique(const value_type& obj)
{
resize(num_elements + 1);//先将hashtable的大小扩充一下。
return insert_unique_noresize(obj);//插入元素。
}
//插入一个元素。
iterator insert_equal(const value_type& obj)
{
resize(num_elements + 1);//先将hashtable的大小扩充一下。
return insert_equal_noresize(obj);
}
pair<iterator, bool> insert_unique_noresize(const value_type& obj);
iterator insert_equal_noresize(const value_type& obj);
//将【f,l)间的元素插入到hashtable中。
#ifdef __STL_MEMBER_TEMPLATES
template <class InputIterator>
void insert_unique(InputIterator f, InputIterator l)
{
insert_unique(f, l, iterator_category(f));
}
template <class InputIterator>
void insert_equal(InputIterator f, InputIterator l)
{
insert_equal(f, l, iterator_category(f));
}
template <class InputIterator>
void insert_unique(InputIterator f, InputIterator l,
input_iterator_tag)
{
for ( ; f != l; ++f)
insert_unique(*f);
}
template <class InputIterator>
void insert_equal(InputIterator f, InputIterator l,
input_iterator_tag)
{
for ( ; f != l; ++f)
insert_equal(*f);
}
template <class ForwardIterator>
void insert_unique(ForwardIterator f, ForwardIterator l,
forward_iterator_tag)
{
size_type n = 0;
distance(f, l, n);
resize(num_elements + n);
for ( ; n > 0; --n, ++f)
insert_unique_noresize(*f);
}
template <class ForwardIterator>
void insert_equal(ForwardIterator f, ForwardIterator l,
forward_iterator_tag)
{
size_type n = 0;
distance(f, l, n);
resize(num_elements + n);
for ( ; n > 0; --n, ++f)
insert_equal_noresize(*f);
}
#else /* __STL_MEMBER_TEMPLATES */
void insert_unique(const value_type* f, const value_type* l)
{
size_type n = l - f;
resize(num_elements + n);
for ( ; n > 0; --n, ++f)
insert_unique_noresize(*f);
}
void insert_equal(const value_type* f, const value_type* l)
{
size_type n = l - f;
resize(num_elements + n);
for ( ; n > 0; --n, ++f)
insert_equal_noresize(*f);
}
void insert_unique(const_iterator f, const_iterator l)
{
size_type n = 0;
distance(f, l, n);
resize(num_elements + n);
for ( ; n > 0; --n, ++f)
insert_unique_noresize(*f);
}
void insert_equal(const_iterator f, const_iterator l)
{
size_type n = 0;
distance(f, l, n);
resize(num_elements + n);
for ( ; n > 0; --n, ++f)
insert_equal_noresize(*f);
}
#endif /*__STL_MEMBER_TEMPLATES */
reference find_or_insert(const value_type& obj);
//查找某个值对应的节点。
iterator find(const key_type& key)
{
//首先算出这个值的hash。
size_type n = bkt_num_key(key);
node* first;
//根据这个hash可以定位到指定的链表buckets[n],然后就在这个链表中查找是否有这个元素。
for ( first = buckets[n];
first && !equals(get_key(first->val), key);
first = first->next)
{}
return iterator(first, this);
}
//查找某个值对应的节点。
const_iterator find(const key_type& key) const
{
size_type n = bkt_num_key(key);
const node* first;
for ( first = buckets[n];
first && !equals(get_key(first->val), key);
first = first->next)
{}
return const_iterator(first, this);
}
//查找某个值对应的节点的数目。
size_type count(const key_type& key) const
{
const size_type n = bkt_num_key(key);//首先算出这个值的hash。
size_type result = 0;
//根据这个hash可以定位到指定的链表buckets[n],然后就在这个链表中查找是否有这个元素,找到一个就累加一次,
//最后返回找到的个数。
for (const node* cur = buckets[n]; cur; cur = cur->next)
if (equals(get_key(cur->val), key))
++result;
return result;
}
pair<iterator, iterator> equal_range(const key_type& key);
pair<const_iterator, const_iterator> equal_range(const key_type& key) const;
size_type erase(const key_type& key);
void erase(const iterator& it);
void erase(iterator first, iterator last);
void erase(const const_iterator& it);
void erase(const_iterator first, const_iterator last);
void resize(size_type num_elements_hint);
void clear();
private:
//返回下一个hash表的大小
size_type next_size(size_type n) const { return __stl_next_prime(n); }
void initialize_buckets(size_type n)
{//首先根据给定的值算出hash表的大小,然后将buckets的代销初始化为该大小。
const size_type n_buckets = next_size(n);
buckets.reserve(n_buckets);
buckets.insert(buckets.end(), n_buckets, (node*) 0);
num_elements = 0;
}
//返回给定值的hash值。
size_type bkt_num_key(const key_type& key) const
{
return bkt_num_key(key, buckets.size());
}
size_type bkt_num(const value_type& obj) const
{
return bkt_num_key(get_key(obj));
}
//返回给定值的hash值,计算方法为 hash(key) % n
size_type bkt_num_key(const key_type& key, size_t n) const
{
return hash(key) % n;
}
size_type bkt_num(const value_type& obj, size_t n) const
{
return bkt_num_key(get_key(obj), n);
}
//申请一个新的节点
node* new_node(const value_type& obj)
{
//申请一个新的内存
node* n = node_allocator::allocate();
n->next = 0;
__STL_TRY {
construct(&n->val, obj);//调用构造函数构造节点中的内部数据
return n;
}
__STL_UNWIND(node_allocator::deallocate(n));
}
//删除某一个节点。
void delete_node(node* n)
{
destroy(&n->val);//先调用析构函数
node_allocator::deallocate(n);//在删除空间
}
void erase_bucket(const size_type n, node* first, node* last);
void erase_bucket(const size_type n, node* last);
void copy_from(const hashtable& ht);
};
//iterator自增运算符
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++()
{
const node* old = cur;
cur = cur->next;//首先看下iterator指向的节点在当前的链表中是否有下一个节点,如果没有,就找到下一个链表的第一个元素。
if (!cur) {
size_type bucket = ht->bkt_num(old->val);//先算出hash值。
while (!cur && ++bucket < ht->buckets.size())//从下一个hash值开始查找有值的链表。
cur = ht->buckets[bucket];
}
return *this;
}
//iterator自增运算符
template <class V, class K, class HF, class ExK, class EqK, class A>
inline __hashtable_iterator<V, K, HF, ExK, EqK, A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++(int)
{
iterator tmp = *this;
++*this;
return tmp;
}
//iterator自增运算符
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_const_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_const_iterator<V, K, HF, ExK, EqK, A>::operator++()
{
const node* old = cur;
cur = cur->next;
if (!cur) {
size_type bucket = ht->bkt_num(old->val);
while (!cur && ++bucket < ht->buckets.size())
cur = ht->buckets[bucket];
}
return *this;
}
//iterator自增运算符
template <class V, class K, class HF, class ExK, class EqK, class A>
inline __hashtable_const_iterator<V, K, HF, ExK, EqK, A>
__hashtable_const_iterator<V, K, HF, ExK, EqK, A>::operator++(int)
{
const_iterator tmp = *this;
++*this;
return tmp;
}
#ifndef __STL_CLASS_PARTIAL_SPECIALIZATION
template <class V, class K, class HF, class ExK, class EqK, class All>
inline forward_iterator_tag
iterator_category(const __hashtable_iterator<V, K, HF, ExK, EqK, All>&)
{
return forward_iterator_tag();
}
template <class V, class K, class HF, class ExK, class EqK, class All>
inline V* value_type(const __hashtable_iterator<V, K, HF, ExK, EqK, All>&)
{
return (V*) 0;
}
template <class V, class K, class HF, class ExK, class EqK, class All>
inline hashtable<V, K, HF, ExK, EqK, All>::difference_type*
distance_type(const __hashtable_iterator<V, K, HF, ExK, EqK, All>&)
{
return (hashtable<V, K, HF, ExK, EqK, All>::difference_type*) 0;
}
template <class V, class K, class HF, class ExK, class EqK, class All>
inline forward_iterator_tag
iterator_category(const __hashtable_const_iterator<V, K, HF, ExK, EqK, All>&)
{
return forward_iterator_tag();
}
template <class V, class K, class HF, class ExK, class EqK, class All>
inline V*
value_type(const __hashtable_const_iterator<V, K, HF, ExK, EqK, All>&)
{
return (V*) 0;
}
template <class V, class K, class HF, class ExK, class EqK, class All>
inline hashtable<V, K, HF, ExK, EqK, All>::difference_type*
distance_type(const __hashtable_const_iterator<V, K, HF, ExK, EqK, All>&)
{
return (hashtable<V, K, HF, ExK, EqK, All>::difference_type*) 0;
}
#endif /* __STL_CLASS_PARTIAL_SPECIALIZATION */
//判断两个hashtable是否相等
template <class V, class K, class HF, class Ex, class Eq, class A>
bool operator==(const hashtable<V, K, HF, Ex, Eq, A>& ht1,
const hashtable<V, K, HF, Ex, Eq, A>& ht2)
{
typedef typename hashtable<V, K, HF, Ex, Eq, A>::node node;
if (ht1.buckets.size() != ht2.buckets.size())//先判断两个hashtable大小是否相等
return false;
for (int n = 0; n < ht1.buckets.size(); ++n) {//然后在一个一个元素比较
node* cur1 = ht1.buckets[n];
node* cur2 = ht2.buckets[n];
for ( ; cur1 && cur2 && cur1->val == cur2->val;
cur1 = cur1->next, cur2 = cur2->next)
{}
if (cur1 || cur2)
return false;
}
return true;
}
#ifdef __STL_FUNCTION_TMPL_PARTIAL_ORDER
template <class Val, class Key, class HF, class Extract, class EqKey, class A>
inline void swap(hashtable<Val, Key, HF, Extract, EqKey, A>& ht1,
hashtable<Val, Key, HF, Extract, EqKey, A>& ht2) {
ht1.swap(ht2);
}
#endif /* __STL_FUNCTION_TMPL_PARTIAL_ORDER */
//插入一个唯一性的元素,不涉及hashtable总大小变更
template <class V, class K, class HF, class Ex, class Eq, class A>
pair<typename hashtable<V, K, HF, Ex, Eq, A>::iterator, bool>
hashtable<V, K, HF, Ex, Eq, A>::insert_unique_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj);//根据元素算出hash。
node* first = buckets[n];//找到该hash对应的链表
//在该链表中查找是否已经有这个元素了,如果有就直接返回。
for (node* cur = first; cur; cur = cur->next)
if (equals(get_key(cur->val), get_key(obj)))
return pair<iterator, bool>(iterator(cur, this), false);
//如果没有找到,就新建一个node,加入链表中,注意这里加入的是链表的头部,而不是尾部。
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return pair<iterator, bool>(iterator(tmp, this), true);
}
//插入一个元素,不涉及hashtable总大小变更
template <class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::iterator
hashtable<V, K, HF, Ex, Eq, A>::insert_equal_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj);//根据元素算出hash。
node* first = buckets[n];//找到该hash对应的链表
//在该链表中查找是否已经有个相等元素了,如果有就在后面新建个节点,连到链表中,这样相同的元素就放到一起了。
for (node* cur = first; cur; cur = cur->next)
if (equals(get_key(cur->val), get_key(obj))) {
node* tmp = new_node(obj);
tmp->next = cur->next;
cur->next = tmp;
++num_elements;
return iterator(tmp, this);//返回新建的节点的iterator。
}
//如果没有找到,就新建一个node,加入链表中。注意这里加入的是链表的头部,而不是尾部。
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return iterator(tmp, this);
}
//查找或新建:有这个元素就直接返回,没有就新建一个返回
template <class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::reference
hashtable<V, K, HF, Ex, Eq, A>::find_or_insert(const value_type& obj)
{
resize(num_elements + 1);//首先对hashtable扩容一下
size_type n = bkt_num(obj);//根据元素算出hash。
node* first = buckets[n];//找到该hash对应的链表。
//在该链表中查找是否已经有个这个元素了,如果有就直接返回。
for (node* cur = first; cur; cur = cur->next)
if (equals(get_key(cur->val), get_key(obj)))
return cur->val;
//如果没有找到,就新建一个node,加入链表中。
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return tmp->val;
}
//返回key对应的iterator(insert_equal时相同的元素放到了一起,因此可以找到起始和终止iterator)
template <class V, class K, class HF, class Ex, class Eq, class A>
pair<typename hashtable<V, K, HF, Ex, Eq, A>::iterator,
typename hashtable<V, K, HF, Ex, Eq, A>::iterator>
hashtable<V, K, HF, Ex, Eq, A>::equal_range(const key_type& key)
{
typedef pair<iterator, iterator> pii;
const size_type n = bkt_num_key(key);//根据元素算出hash。
for (node* first = buckets[n]; first; first = first->next) {
if (equals(get_key(first->val), key)) //首先看下链表的中的第一个和key相等的元素。
{
for (node* cur = first->next; cur; cur = cur->next)
if (!equals(get_key(cur->val), key))//找到该链表中最后一个相等的。
return pii(iterator(first, this), iterator(cur, this));
//如果该链表中的最后一个元素也和Key相等,就认为终止iterator为下一个链表的起始节点(由于节点所属链表是hash计算的,因此下一个链表绝对不会有Key,因此无需判断)
for (size_type m = n + 1; m < buckets.size(); ++m)
if (buckets[m])
return pii(iterator(first, this),
iterator(buckets[m], this));
return pii(iterator(first, this), end());
}
}
//没有找到key,返回End
return pii(end(), end());
}
//返回key对应的iterator(insert_equal时相同的元素放到了一起,因此可以找到起始和终止iterator)
template <class V, class K, class HF, class Ex, class Eq, class A>
pair<typename hashtable<V, K, HF, Ex, Eq, A>::const_iterator,
typename hashtable<V, K, HF, Ex, Eq, A>::const_iterator>
hashtable<V, K, HF, Ex, Eq, A>::equal_range(const key_type& key) const
{
typedef pair<const_iterator, const_iterator> pii;
const size_type n = bkt_num_key(key);
for (const node* first = buckets[n] ; first; first = first->next) {
if (equals(get_key(first->val), key)) {
for (const node* cur = first->next; cur; cur = cur->next)
if (!equals(get_key(cur->val), key))
return pii(const_iterator(first, this),
const_iterator(cur, this));
for (size_type m = n + 1; m < buckets.size(); ++m)
if (buckets[m])
return pii(const_iterator(first, this),
const_iterator(buckets[m], this));
return pii(const_iterator(first, this), end());
}
}
return pii(end(), end());
}
//删除某个key
template <class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::size_type
hashtable<V, K, HF, Ex, Eq, A>::erase(const key_type& key)
{
const size_type n = bkt_num_key(key);//根据元素算出hash。
node* first = buckets[n];
size_type erased = 0;
if (first) {
node* cur = first;
node* next = cur->next;
while (next) {
if (equals(get_key(next->val), key)) {
cur->next = next->next;
delete_node(next);//找到一个,就从链表中去除,然后删掉。
next = cur->next;
++erased;
--num_elements;
}
else {
cur = next;
next = cur->next;
}
}
if (equals(get_key(first->val), key)) {
buckets[n] = first->next;
delete_node(first);
++erased;
--num_elements;
}
}
return erased;
}
//删除某个iterator对应的节点。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::erase(const iterator& it)
{
if (node* const p = it.cur) {
const size_type n = bkt_num(p->val);//先算出该iterator的hash
node* cur = buckets[n];//找到该hash对应的链表。
if (cur == p) {
buckets[n] = cur->next;
delete_node(cur);
--num_elements;
}
else {
node* next = cur->next;
while (next) {
if (next == p) {
cur->next = next->next;
delete_node(next);
--num_elements;
break;
}
else {
cur = next;
next = cur->next;
}
}
}
}
}
//删除某个first到last之间所有的节点。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::erase(iterator first, iterator last)
{
//首先获取到first和last在hashtable中所属的链表
size_type f_bucket = first.cur ? bkt_num(first.cur->val) : buckets.size();
size_type l_bucket = last.cur ? bkt_num(last.cur->val) : buckets.size();
if (first.cur == last.cur)//如果first和last指向相同,直接返回
return;
else if (f_bucket == l_bucket)//如果first和last在同一个链表中,直接删除即可。
erase_bucket(f_bucket, first.cur, last.cur);
else {//不在同一个链表中,删除的元素就比较多了,
erase_bucket(f_bucket, first.cur, 0);//先删除first链表中从first开始的所有元素。
for (size_type n = f_bucket + 1; n < l_bucket; ++n)//然后删除两个链表之间的链表中的所有元素
erase_bucket(n, 0);
if (l_bucket != buckets.size())
erase_bucket(l_bucket, last.cur);//最后删掉last中从头到last的所有元素。
}
}
//删除某个first到last之间所有的节点。
template <class V, class K, class HF, class Ex, class Eq, class A>
inline void
hashtable<V, K, HF, Ex, Eq, A>::erase(const_iterator first,
const_iterator last)
{
erase(iterator(const_cast<node*>(first.cur),
const_cast<hashtable*>(first.ht)),
iterator(const_cast<node*>(last.cur),
const_cast<hashtable*>(last.ht)));
}
template <class V, class K, class HF, class Ex, class Eq, class A>
inline void
hashtable<V, K, HF, Ex, Eq, A>::erase(const const_iterator& it)
{
erase(iterator(const_cast<node*>(it.cur),
const_cast<hashtable*>(it.ht)));
}
//重新设置hashtable的大小
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::resize(size_type num_elements_hint)
{
const size_type old_n = buckets.size();
if (num_elements_hint > old_n) {//如果希望存储的数目大于当前hashtable中的数目,那么就用希望的数目去__stl_prime_list里找一个合适的链表数目,
//如果链表数目大于当前hashtable中的节点的数目,就扩容。
//这里的原理个人猜测:根据hash的求余规则,如果计算出的链表数目大于当前hashtable中的数目,说明链表开链比较严重了,扩容之后,
//根据求余规则平均下来每个链表最多只有一个元素。
const size_type n = next_size(num_elements_hint);
if (n > old_n) {
vector<node*, A> tmp(n, (node*) 0);//先申请一个新的vector,
__STL_TRY {
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket];//遍历老的vector,将每个元素重新hash一下,放到新的vector中。
while (first) {
size_type new_bucket = bkt_num(first->val, n);
buckets[bucket] = first->next;
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
first = buckets[bucket];
}
}
buckets.swap(tmp);//然后将新的vector赋值给buckets
}
# ifdef __STL_USE_EXCEPTIONS
catch(...) {
for (size_type bucket = 0; bucket < tmp.size(); ++bucket) {
while (tmp[bucket]) {
node* next = tmp[bucket]->next;
delete_node(tmp[bucket]);//出错比较奇怪,会删掉已经重新hash的node。
tmp[bucket] = next;
}
}
throw;
}
# endif /* __STL_USE_EXCEPTIONS */
}
}
}
//删除某个链表上的first到last的节点(注意参数是node*,不是iterator)
//这个函数比较奇怪,个人猜测和上面的调用逻辑有关系 ╮(╯▽╰)╭
//如果first为链表头,那么会从头删到last
//如果first不为链表头,那么从first一直删除到最后。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::erase_bucket(const size_type n,
node* first, node* last)
{
node* cur = buckets[n];//首先定位到要删除的链表
if (cur == first)//如果first为链表头,那么直接从头开始删除
erase_bucket(n, last);
else {
node* next;//循环查找节点值为first的节点。
for (next = cur->next; next != first; cur = next, next = cur->next)
;
//找到之后开删除,一直删除到最后。这里比较奇怪。
while (next) {
cur->next = next->next;
delete_node(next);
next = cur->next;
--num_elements;
}
}
}
//删除某个链表上的节点,从头开始删除到last(注意参数是node*,不是iterator)
template <class V, class K, class HF, class Ex, class Eq, class A>
void
hashtable<V, K, HF, Ex, Eq, A>::erase_bucket(const size_type n, node* last)
{
node* cur = buckets[n];
while (cur != last) {
node* next = cur->next;
delete_node(cur);
cur = next;
buckets[n] = cur;
--num_elements;
}
}
//清除hashtable中的所有元素。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::clear()
{
for (size_type i = 0; i < buckets.size(); ++i) {
node* cur = buckets[i];
while (cur != 0) {
node* next = cur->next;
delete_node(cur);
cur = next;
}
buckets[i] = 0;
}
num_elements = 0;
}
//从另一个hashtable中拷贝。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::copy_from(const hashtable& ht)
{
buckets.clear();//先把本地的删干净
buckets.reserve(ht.buckets.size());//把buckets先拷贝过来。
buckets.insert(buckets.end(), ht.buckets.size(), (node*) 0);
__STL_TRY {//然后把所有的节点拷贝过来。
for (size_type i = 0; i < ht.buckets.size(); ++i) {
if (const node* cur = ht.buckets[i]) {
node* copy = new_node(cur->val);
buckets[i] = copy;
for (node* next = cur->next; next; cur = next, next = cur->next) {
copy->next = new_node(next->val);
copy = copy->next;
}
}
}
num_elements = ht.num_elements;
}
__STL_UNWIND(clear());
}
发表评论